




Kafka启动与示例
编辑
为什么使用Kafka
Kafka 是一个分布式消息队列,核心的功能是用来连接消息发送者和消息接收者。
除此之外还有以下特点:
可以持久化:进入的消息不会丢失,可以多次读取,可以记录读取位置。
高吞吐量:支持短时间内处理大量数据。
可扩展:容易横向扩展,提高数据处理能力。
核心概念
Broker:工人,收发请求和存储数据。
Controller:工头,工人里选出来的,用来管理和协调集群状态。
Topic(主题):仓库,存储特定分类的消息。
Partition(分区):货架,存放消息,货架上的货物先进先出。
ZooKeeper/KRaft:人事部,负责工头的选举,确保集群的稳定运行。
ZooKeeper和KRaft功能相同,KRaft在新版本中集成,无需再额外依赖ZooKeeper,减少了运维成本。
Docker快速启动
环境要求:已安装Docker以及Compose组件
使用下面Docker Compose配置文件快速启动一个单节点的Kafka用于测试。
compose.yaml
services:
kafka:
image: bitnami/kafka:latest
container_name: kafka
ports:
- "9092:9092" # 客户端访问端口
- "9093:9093" # 节点间通信端口
environment:
- KAFKA_ENABLE_KRAFT=yes # 启用KRaft模式
- KAFKA_CFG_PROCESS_ROLES=broker,controller # 设置角色
- KAFKA_CFG_NODE_ID=1 # 设置节点ID 唯一标识
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka:9093 # 设置KRaft控制器列表 集群可以添加多个
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 # 设置监听器
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 # 设置对外公开的监听器端口
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 使用不加密协议设置监听器
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER # 使用CONTROLLER监听器监听通信
- ALLOW_PLAINTEXT_LISTENER=yes # 允许PLAINTEXT协议
volumes:
- ./kafka-data:/bitnami/kafka:rw在服务器上创建一个名为kafka 的文件夹并进入,将上述配置保存为compose.yaml 文件。
使用docker compose up -d 启动项目,使用docker compose logs -f 查看项目日志。
测试服务可用性
使用下面查看日志确认服务就绪,如果输出“Kafka Server started (kafka.server.KafkaRaftServer)”则代表启动成功。
docker compose logs -f | grep started使用命令行工具查看消息发送与接收的效果。需要打开两个命令行,根据下面提示输入命令查看效果。
# 命令行1(消费者) 执行下面两句命令
# 创建一个topic 名为test
docker exec kafka kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test
# 监听名为test的topic 执行后进入阻塞等待接收消息
docker exec kafka kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
# 命令行2(生产者) 执行下面命令
# 命令行进入阻塞状态,输入要发送的消息,回车发送,Ctrl + D 退出发送模式
docker exec -it kafka kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test执行效果如下,左侧为消费者,右侧为生产者。如果达成下面的效果就说明服务可以正常使用了。
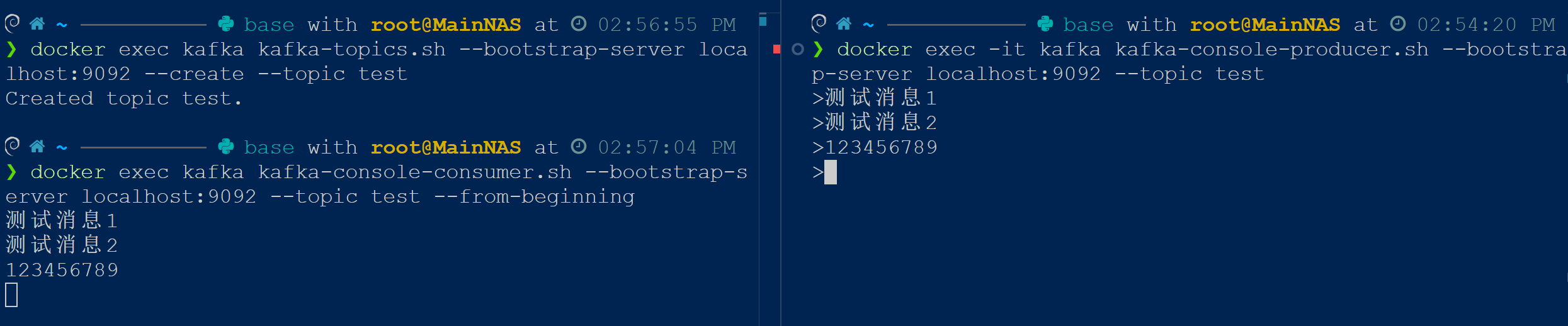
Python使用示例
环境要求:已安装Python3,并安装kafka-python库
kafka-python安装:pip install kafka-python
下面代码模拟传递Json类型的消息,也可以使用其他格式的内容作为消息传递,比如图片,音视频内容。但由于Kafka传递字节类型的消息,需要自行编写消息序列化函数。
消费者代码
consumer.py
from kafka import KafkaConsumer
import json
import time
topic_name = "json-py" # 指定接收的topic
server = "localhost:9092" # 指定服务器
consumer = KafkaConsumer(
topic_name,
bootstrap_servers=server,
auto_offset_reset="earliest", # 默认取最早的消息
enable_auto_commit=True, # 读取内容自动提交
group_id="demo_group", # 接收组的ID
value_deserializer=lambda v: json.loads(v) if v else {}, # 反序列化函数
)
for msg in consumer:
print("接收:", msg.value)
time.sleep(0.1)生产者代码
producer.py
from datetime import datetime
from kafka import KafkaProducer
import json
import time
topic_name = "json-py" # 指定接收的topic
server = "localhost:9092" # 指定服务器
producer = KafkaProducer(
bootstrap_servers=server,
value_serializer=lambda v: json.dumps(v).encode("utf-8"), # 序列化函数
)
for i in range(10):
msg = {
"id": i,
"msg": f"消息发送时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}",
}
producer.send(topic=topic_name, value=msg)
print("发送:", msg)
time.sleep(1)
producer.flush()
producer.close()启动验证
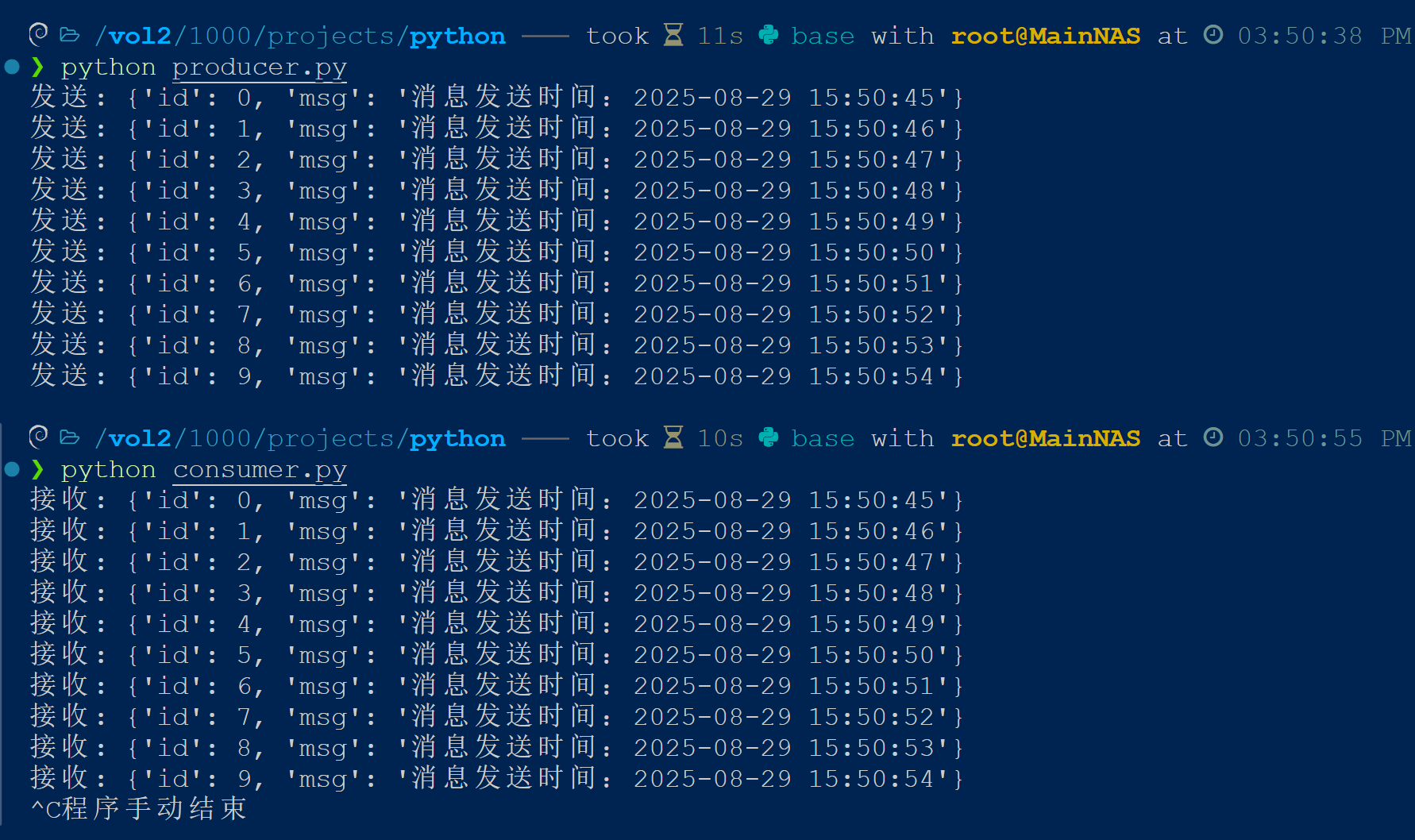
执行结果
正常执行结果
模拟消费者处理中断
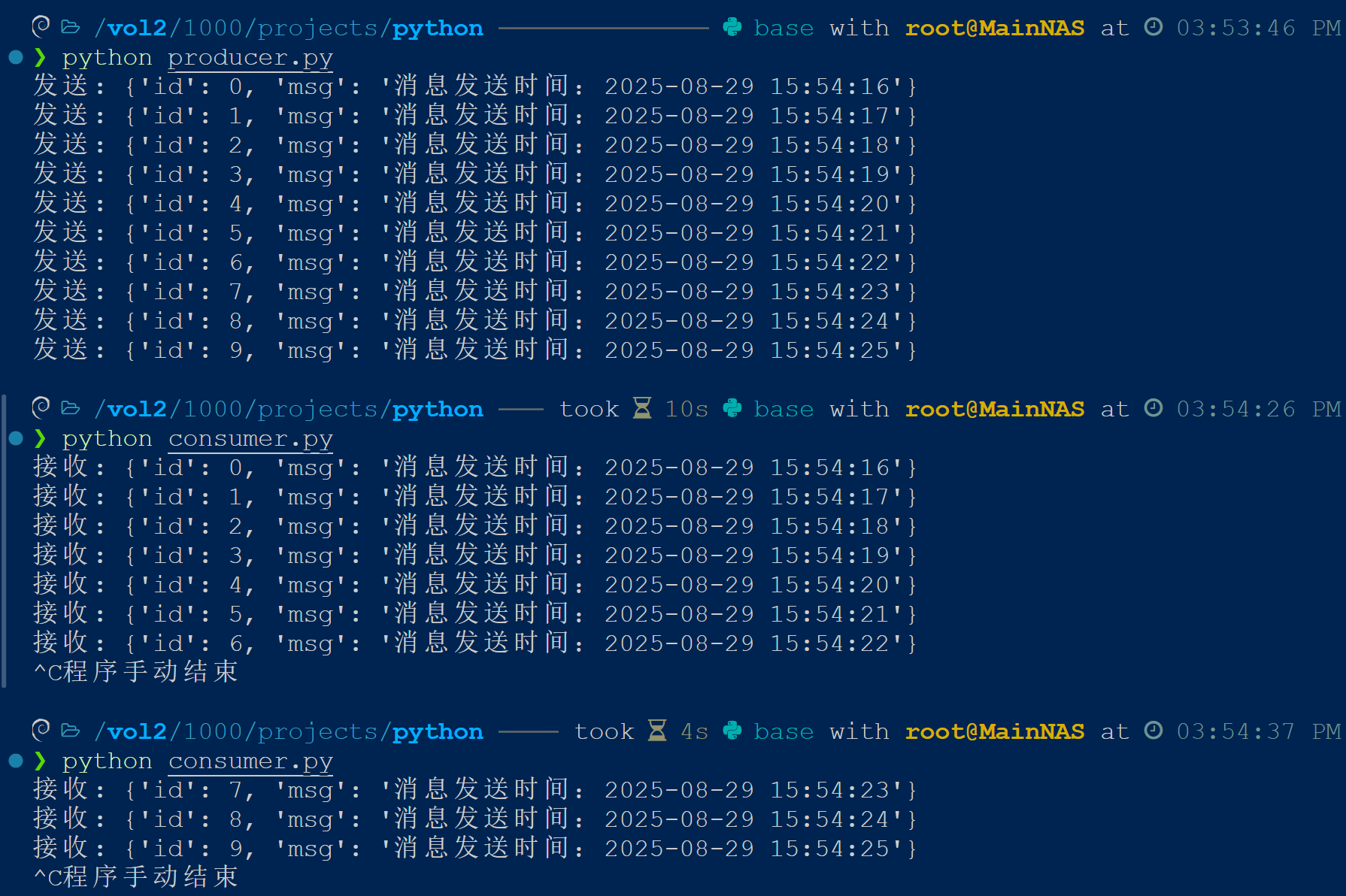
由于使用Kafka作为中间件,即使先启动生产者,消费者端依然可以获取到生产者发出的所有消息。
并且即使消费者端中断处理,下次执行时仍然可以从中断处继续执行。
- 0
- 0
-
分享